Projection and \(A=QR\)#
Definition: Span
The span of a set of vectors \(\{\mathbf{v}_1, \dots, \mathbf{v}_k\}\) is the set of all linear combinations \(c_1\mathbf{v_1} + \cdots + c_k\mathbf{v}_k\).
The span of a set of vectors is a geometric object.
Example: The span of a single vector \(\mathbf{v}\) is the line in the direction of \(\mathbf{v}\). A linear combination in the case of a single vector is just a scalar multiple of the vector, and that will point either in the same direction or the exact opposite direction if the sign of the scalar is negative.
Example: The span of two linearly independent vectors three dimensional vectors is a plane. We can see this easily, for example, with vectors like
whose linear combinations produce all vectors in the \(x\)-\(y\) plane and none that are not in the \(x\)-\(y\) plane because of the 0 in the third component.
Given a set of vectors \(\{\mathbf{v}_1,\dots, \mathbf{v}_k\}\) and another vector \(\mathbf{b}\) that is not in their span, one can ask for the vector in the span of \(\{\mathbf{v}_1,\dots, \mathbf{v}_k\}\) ‘nearest’ to \(\mathbf{b}\). We define the nearest vector to \(\mathbf{b}\) in the span of \(\{\mathbf{v}_1,\dots, \mathbf{v}_k\}\) to be the vector \(\mathbf{p}\) for which the distance from the terminus of \(\mathbf{b}\) to the terminus of \(\mathbf{p}\) is as small as possible. This is sketched in two and three dimensions below.
import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
plt.style.use('bmh')
# Create figure with two subplots
fig = plt.figure(figsize=(14, 6))
# Left plot: 2D vector projection of b onto a
ax1 = fig.add_subplot(121)
# Define vectors - make 'a' significantly longer
a = np.array([6, 3])
b = np.array([2.5, 3])
# Calculate projection of b onto a
proj_b_onto_a = (np.dot(b, a) / np.dot(a, a)) * a
# Plot vectors
ax1.quiver(0, 0, a[0], a[1], angles='xy', scale_units='xy', scale=1, color='red', width=0.005, label='Vector a')
ax1.quiver(0, 0, b[0], b[1], angles='xy', scale_units='xy', scale=1, color='blue', width=0.005, label='Vector b')
ax1.quiver(0, 0, proj_b_onto_a[0], proj_b_onto_a[1], angles='xy', scale_units='xy', scale=1, color='green', width=0.005, label='proj_a(b)')
# Draw the perpendicular line from b to its projection
ax1.plot([b[0], proj_b_onto_a[0]], [b[1], proj_b_onto_a[1]], 'k--', alpha=0.7, linewidth=1)
# Add right angle marker
perp_vec = b - proj_b_onto_a
if np.linalg.norm(perp_vec) > 0:
# Create a small square to show right angle
corner_size = 0.3
corner_start = proj_b_onto_a
a_unit = a / np.linalg.norm(a)
perp_unit = perp_vec / np.linalg.norm(perp_vec)
corner_points = np.array([
corner_start,
corner_start + corner_size * a_unit,
corner_start + corner_size * a_unit + corner_size * perp_unit,
corner_start + corner_size * perp_unit,
corner_start
])
ax1.plot(corner_points[:, 0], corner_points[:, 1], 'k-', linewidth=0.8)
# Set equal aspect ratio and add grid
ax1.set_xlim(-0.5, 7)
ax1.set_ylim(-0.5, 4)
ax1.set_aspect('equal')
ax1.grid(True, alpha=0.3)
ax1.legend()
ax1.set_title('Projection of Vector b onto Vector a')
ax1.set_xlabel('x')
ax1.set_ylabel('y')
# Add vector labels
ax1.text(a[0]/2 - 0.2, a[1]/2 + 0.2, 'a', fontsize=12, color='red', weight='bold')
ax1.text(b[0]/2 + 0.2, b[1]/2 + 0.2, 'b', fontsize=12, color='blue', weight='bold')
ax1.text(proj_b_onto_a[0]/2, proj_b_onto_a[1]/2 - 0.3, 'proj_a(b)', fontsize=10, color='green', weight='bold')
# Right plot: 3D vector projection onto xy-plane
ax2 = fig.add_subplot(122, projection='3d')
# Define a 3D vector - moved to better show basis vectors
v_3d = np.array([2.5, 2.5, 4])
# Projection onto xy-plane (z=0)
v_proj_xy = np.array([v_3d[0], v_3d[1], 0])
# Plot the original 3D vector
ax2.quiver(0, 0, 0, v_3d[0], v_3d[1], v_3d[2], color='blue', arrow_length_ratio=0.1, linewidth=3, label='Vector v')
# Plot the projection onto xy-plane
ax2.quiver(0, 0, 0, v_proj_xy[0], v_proj_xy[1], v_proj_xy[2], color='red', arrow_length_ratio=0.1, linewidth=3, label='proj_xy(v)')
# Add basis vectors e1 and e2 for the xy-plane
e1 = np.array([1, 0, 0]) # x-axis basis vector
e2 = np.array([0, 1, 0]) # y-axis basis vector
ax2.quiver(0, 0, 0, e1[0], e1[1], e1[2], color='orange', arrow_length_ratio=0.2, linewidth=2, label='e₁')
ax2.quiver(0, 0, 0, e2[0], e2[1], e2[2], color='purple', arrow_length_ratio=0.2, linewidth=2, label='e₂')
# Draw the perpendicular line from vector tip to its projection
ax2.plot([v_3d[0], v_proj_xy[0]], [v_3d[1], v_proj_xy[1]], [v_3d[2], v_proj_xy[2]], 'k--', alpha=0.7, linewidth=2)
# Create xy-plane as a transparent surface
xx, yy = np.meshgrid(np.linspace(-1, 4, 10), np.linspace(-1, 3, 10))
zz = np.zeros_like(xx)
ax2.plot_surface(xx, yy, zz, alpha=0.2, color='gray')
# Add plane outline
plane_x = [-1, 4, 4, -1, -1]
plane_y = [-1, -1, 3, 3, -1]
plane_z = [0, 0, 0, 0, 0]
ax2.plot(plane_x, plane_y, plane_z, 'k-', alpha=0.5, linewidth=1)
# Set labels and title
ax2.set_xlabel('x')
ax2.set_ylabel('y')
ax2.set_zlabel('z')
ax2.set_title('Projection of 3D Vector onto xy-plane')
ax2.legend()
# Set equal aspect ratio for 3D plot
max_range = 4
ax2.set_xlim([0, max_range])
ax2.set_ylim([0, max_range])
ax2.set_zlim([0, max_range])
# Add vector labels
ax2.text(v_3d[0]/2 + 0.2, v_3d[1]/2, v_3d[2]/2 + 0.2, 'v', fontsize=12, color='blue', weight='bold')
ax2.text(v_proj_xy[0]/2, v_proj_xy[1]/2 + 0.2, v_proj_xy[2], 'proj_xy(v)', fontsize=10, color='red', weight='bold')
ax2.text(e1[0] + 0.1, e1[1], e1[2] + 0.1, 'e₁', fontsize=12, color='orange', weight='bold')
ax2.text(e2[0], e2[1] + 0.1, e2[2] + 0.1, 'e₂', fontsize=12, color='purple', weight='bold')
ax2.text(2, 1.5, 0.1, 'xy-plane', fontsize=10, color='gray', style='italic')
plt.tight_layout()
plt.show()
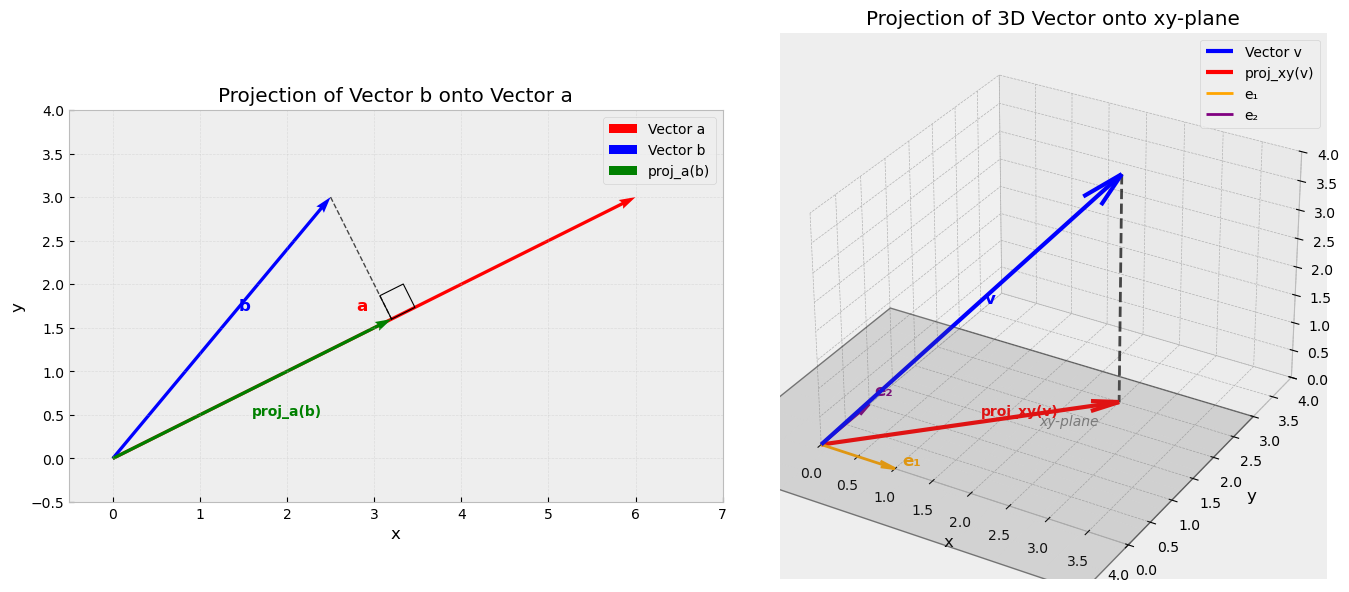
Projection onto a Single Vector#
In the example illustrated above on the left, \(\mathbf{b}\) is being projected onto the span of \(\mathbf{a}\), which is simply the line in the direction that \(\mathbf{a}\) points. So \(\mathbf{p}\) must be a scalar multiple of \(\mathbf{a}\); that is, \(\mathbf{p} = x\mathbf{a}\), and determining \(\mathbf{p}\) amounts simply to determining the correct scalar \(x\).
To determine \(x\), note that the distance between the termini of the two vectors is shortest when a ray drawn from the tip of \(\mathbf{b}\) forms a right angle with \(\mathbf{a}\). This coincides with the terminus of the projection \(\mathbf{p}\) that we are trying to determine, and the ray can be expressed as a vector \(\mathbf{e} = \mathbf{b} - \mathbf{p}\) (sketch this yourself using the parallelogram rule for vector addition if you’re not convinced). Vectors at right angles have a dot product of 0.
Definition: Orthogonality
Vectors \(\mathbf{v}_1\), \(\mathbf{v}_2\) are said to be orthogonal if \(\mathbf{v}_1^T\mathbf{v}_2 = 0\). A set of vectors \(\mathbf{v}_1, \dots, \mathbf{v}_k\) is orthogonal if \(\mathbf{v}_i^T\mathbf{v}_j = 0\) for all \(1\leq i, j \leq k\) such that \(i \neq j\). If all of the vectors are unit vectors, we call the set orthonormal.
‘Orthogonal’ is a term that means the same thing as ‘perpendicular’ when working with lines, planes, and so on, but is also used more generally to describe similar notions with things that are non necessarily linear (see, for example, orthogonal functions).
The vectors \(\mathbf{e}\) and \(\mathbf{a}\) are orthogonal, so \(\mathbf{a}^T\mathbf{e} = 0\). We can use this to solve for \(x\):
and once we know \(x\) we know \(\mathbf{p} = x\mathbf{a}\).
Example: Given \(\mathbf{u}\) and \(\mathbf{v}\), below, we will calculate the projection \(\mathbf{p}\) of \(\mathbf{u}\) onto the line spanned by \(\mathbf{v}\):
Then
and
Now suppose that instead of projecting onto a line spanned by a single vector, we want to project a vector \(\mathbf{b}\) onto the span of several vectors \(A_1, \dots, A_n\). As you can probably guess from the choice of notation, these vectors are going to end up in the columns of a matrix shortly, but for the moment we will simply set the same ‘nearness’ condition for the projection; that is, for each \(A_i\), \(1\leq i\leq n\) we want to determine \(x_i\) so that \(A_i^T(\mathbf{b} - xA_i) = 0\). This gives us a system:
This system can be better written as the matrix equation
and this can be solved for \(\mathbf{x}\):
Then, as in the single-vector case, the projection can be found by multiplying the \(A_i\)’s by \(\mathbf{x}\):
Similarity to the Normal Equation from OLS#
Before going further, note the similarity with the normal equation \(\mathbf{b} = (X^TX)^{-1}X^T\mathbf{y}\) from the last section. In the normal equation, \(X\) contains our input data, \(\mathbf{y}\) is a vector of known values, and \(\mathbf{b}\) represents a vector of unknowns, and these can be translated to the projection formula’s \(A\), \(\mathbf{b}\), and \(\mathbf{x}\) respectively. Aside from the different choice of variable names, we have the same formula for the unknowns: \((A^TA)^{-1}A^T\mathbf{b} = \mathbf{x}\), and we derive the predictions in OLS in the same way we obtain the projection vector once we have \(\mathbf{x}\): \(X\mathbf{b} = X(X^TX)^{-1}X^T\mathbf{y}\) for OLS or \(A\mathbf{x} = A(A^TA)^{-1}A^T\mathbf{b}\) for projection. This provides a geometric explanation for why the normal equation is the right solution to the problem of fitting a line: the normal equation produces the coefficients that map \(\mathbf{y}\) into the span of the data in the columns of \(X\) so that we land on the nearest vector to \(\mathbf{y}\) that is in the span of the columns of \(X\).
Since we have arrived back at the normal equation, we have also arrived back at the question we ended the last section with: how can we compute these quantities without inverting \(A^TA\)?
Gram-Schmidt Orthogonalization#
Given a set of vectors \(\mathbf{v}_1,\dots, \mathbf{v}_k\), it is possible to algorithmically produce a set of vectors \(\mathbf{q}_1,\dots,\mathbf{q}_k\) that have the same span but are orthogonal to each other. The process of doing so it called Gram-Schmidt orthogonalization.
The Gram-Schmidt Orthogonalization Algorithm
Set \(\mathbf{q_1} = \mathbf{v_1}\).
Set \(\mathbf{q_2} = \mathbf{v}_2 - \text{proj}_{\mathbf{q}_1}(\mathbf{v}_2)\), where \(\text{proj}_{\mathbf{q}_1}(\mathbf{v}_2)\) denotes the projection of \(\mathbf{v}_2\) in the direction of \(\mathbf{q}_1\).
Set \(\mathbf{q_3} = \mathbf{v_3} - \text{proj}_{\mathbf{q}_1}(\mathbf{v}_3) - \text{proj}_{\mathbf{q}_2}(\mathbf{v}_3)\).
Continue this process until you have produced \(k\) orthogonal vectors \(\mathbf{q}_1,\dots,\mathbf{q}_k\).
It is common to extend this process slightly to produce an orthonormal set by dividing each \(\mathbf{q}_i\) by its length after obtaining it from the above process. Doing so is then called the Gram-Schmidt orthonormalization process.
We can verify (somewhat tediously) that the process above produces vectors that are orthogonal to each other. What about their span? When \(\mathbf{q}_2\) is formed following the algorithm above, we have simply produced a vector analagous to the vector \(\mathbf{e} = \mathbf{b} - \mathbf{p}\) from our earlier derivation of the projection formula. This changes \(\mathbf{v}_2\), but not the directional piece of \(\mathbf{v}_2\) that differs from the direction of \(\mathbf{v}_1\), and this means that the result is a set of vectors \(\mathbf{q}_1, \mathbf{q}_2\) that span the same space as the original \(\mathbf{v}_1, \mathbf{v}_2\). Further iterations of the process are messier but follow the same logic.
More formally, note that each \(\mathbf{q}_i\) is simply a linear combination of the \(\mathbf{v}_j\)’s, which means that each \(\mathbf{q}_i\) is in the span of the \(\mathbf{v}_j\)’s, and so any linear combination of the \(\mathbf{q}_i\)’s must also be in the span of the \(\mathbf{v}_j\)’s. Conversely, suppose \(\mathbf{x}\) is a vector in the span of the \(\mathbf{v}_i\)’s. In the above algorithm, move each of the proj\(_{\mathbf{q}_i}(\mathbf{v}_j)\)’s to the left-hand side: each such projection is by definition a scalar multiple of the vector \(\mathbf{q}_i\) being projected onto, so the \(\mathbf{v}_j\)’s are in the span of the \(\mathbf{q}_i\)’s also. Thus, the spans must be the same.
\(A = QR\) via Gram-Schmidt#
The above algorithm extends naturally to the factorization that is our goal: \(A = QR\). We just showed that given a set of vectors \(\mathbf{v}_1,\dots, \mathbf{v}_k\), it is possible to algorithmically produce a set of vectors \(\mathbf{q}_1,\dots,\mathbf{q}_k\) that have the same span but are orthogonal to each other. In showing this, we noted that each \(\mathbf{v}_j\) is expressible as a linear combination of the \(\mathbf{q}_i\)’s; in particular,
where the \(r_j\)’s are corresponding projection coefficients. So let’s do this using the columns of a square \(n\times n\) matrix \(A\) as the \(\mathbf{v}_i\)’s, and write all of these linear combinations in a matrix multiplication:
Go one step further and for each \(j\), \(1\leq j \leq n\), multiply each column \(\mathbf{q}_j\) in the matrix on the left by \(1/||\mathbf{q}_j||\), and each column in the matrix on the right by \(||\mathbf{q}_j||\). Now \(A = QR\) and \(Q\) is a matrix with not just orthogonal but orthonormal columns.
Orthogonal Matrices#
Definition: Orthogonal Matrix
A matrix \(Q\) is an orthogonal matrix if the columns of \(Q\) are orthonormal
You will have to put up with the inconsistency in the language, because it is standard. The orthonormality of the columns of an orthogonal matrix leads to some important characteristics.
Properties of Orthogonal Matrices
\(Q^{-1} = Q^T\) (so \(Q^TQ=I\))
\((Q\mathbf{x})^T(Q\mathbf{y}) = \mathbf{x}^T\mathbf{y}\) (multiplication by \(Q\) preserves dot products)
\(||Q\mathbf{x}|| = ||\mathbf{x}||\) (multiplication by \(Q\) preserves norms)
The properties above are all easily proved in order from the definitions and their proofs are left as an exercise.
Going back to the normal equations from OLS, you can recognize the \(QR\) factorization as the one that will allow us to get around having to calculate \((A^TA)^{-1}\). The argument from the conclusion of the previous section is reproduced below:
This works because \(Q\) is orthogonal, so it is its own inverse. \(R\) is upper triangular, so solving from \(Q^T\mathbf{y} = R\mathbf{b}\) only requires back substitution. However, there is still one issue: the \(QR\)-factorization for a square matrix is slightly different that the \(QR\)-factorization of a nonsquare matrix, and \(X\) in OLS is \(m\times n\), typically with \(m >> n\).
The Thin \(QR\)-Factorization#
If \(A\) is \(m\times n\) and \(m\neq n\), then we can still obtain a \(QR\)-factorization of \(A\), but it will not be unique. It is easiest to express the factorization using block matrices. Block matrices are simply a conceptualization of a matrix as a collection of compatible submatrices; for example, I could write a \(4\times4\) matrix \(A\) using \(2\times2\) blocks:
Here each \(A_{ij}\) is a \(2\times2\) matrix; in particular,
the components in the ‘upper left corner’ and ‘lower right corner’ of \(A\) itself. Now, it is important to know that multiplication with compatible block matrices is the same as multiplication with ordinary matrices; for example,
using the standard row method.
If we compute a \(QR\)-factorization of an \(m\times n\) matrix \(A\) with \(m \geq n\) the result can be expressed in the following block form:
where \(Q\) is \(m\times m\), \(R\) is \(m\times n\), \(Q_1\) is \(m\times n\), \(Q_2\) is \(m\times (m-n)\), \(R_1\) is \(n\times n\), and the zero in \(R\) represents an \((m-n) \times n\) zero matrix. In this scenario, under reasonable hypotheses \(Q_1\) and \(R_1\) are unique but \(Q_2\) is not, hence our phrasing of this as a \(QR\)-factorization rather than the \(QR\) factorization. For OLS, \(Q_1\) and \(R_1\) are where we want to focus.
Calculation of Thin QR
The Gram-Schmidt process is not typically used to produce the thin \(QR\) factorization. Later on we will show how it is calculated using Householder reflections.
An Example ‘by Hand’#
Consider a simple case where we can perform OLS by hand (Python will do the computations). We will use only three points that are not collinear and we will find the parameters of the line of best fit using \(Q^T\mathbf{y} = R\mathbf{b}\) instead of \(\mathbf{b} = (A^TA)^{-1}A^T\mathbf{y}\).
X = np.array([[1, 1], [2, 1], [3, 1]])
y = np.array([[1], [1], [2]])
plt.scatter(X[:, 0], y);
The data are already separated into the vector \(\mathbf{y}\) and matrix \(X\) with column of ones corresponding to the intercept. We will solve using \(Q^T\mathbf{y} = R\mathbf{b}\), so we need the \(QR\)-factorization of \(X\).
from scipy import linalg as linalg
Q, R = linalg.qr(X)
Q, R
(array([[-0.26726124, 0.87287156, 0.40824829],
[-0.53452248, 0.21821789, -0.81649658],
[-0.80178373, -0.43643578, 0.40824829]]),
array([[-3.74165739, -1.60356745],
[ 0. , 0.65465367],
[ 0. , 0. ]]))
As can be seen, \(Q\) is \(3\times 3\), while \(R\) is \(3\times 2\) with the last row consisting solely of zeros. Let’s partition \(R\) into \(R_1\) (the important part) and what will be called the zero_part_of_R.
R1 = R[:2, :]
zero_part_of_R = R[2:, :]
R1
array([[-3.74165739, -1.60356745],
[ 0. , 0.65465367]])
zero_part_of_R
array([[0., 0.]])
Now we partition \(Q\) into \(Q_1\) (the unique and important part) and \(Q_2\) (the not necessarily unique and unimportant part).
Q1 = Q[:, :2]
Q2 = Q[:, 2:]
Q1
array([[-0.26726124, 0.87287156],
[-0.53452248, 0.21821789],
[-0.80178373, -0.43643578]])
Q2
array([[ 0.40824829],
[-0.81649658],
[ 0.40824829]])
Now, we use only \(Q_1\) and \(R_1\) in \(Q^T\mathbf{y} = R\mathbf{b}\), not the full matrices. First, get \(Q_1^T\mathbf{y}\):
LHS = Q1.T @ y
LHS
array([[-2.40535118],
[ 0.21821789]])
And then backsubstitute in upper-triangular \(R_1\) to find \(\mathbf{b}\) (we will use a solver routine for this):
b = linalg.solve(R1, LHS)
b
array([[0.5 ],
[0.33333333]])
Let’s plot the line:
plt.scatter(X[:, 0], y)
xs = np.linspace(0, 4)
plt.plot(xs, b[0] * xs + b[1], color='red', label='line of best fit')
plt.legend(loc='best');
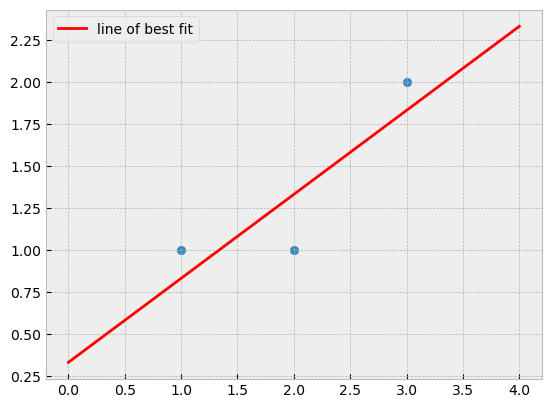
It looks good, but how does it compare with the solution obtained using the normal equation?
linalg.inv(X.T@X) @ X.T @ y
array([[0.5 ],
[0.33333333]])
That is the same vector \(\mathbf{b}\), but we were able to avoid computing \((A^TA)^{-1}\) by instead calculating \(A=QR\).
A Real-World Example#
Let’s use the student performance data from the last section. Below are the same preprocessing steps:
import pandas as pd
df = pd.read_csv('./datasets/Student_Performance.csv')
df = pd.get_dummies(df)
y = df['Performance Index'].values # separate the target variable from the input data
df['Intercept'] = np.ones(shape=(10000,)) # add the intercept column of 1's
df = df.drop(['Extracurricular Activities_No', 'Performance Index'], axis=1) # drop the target and the redundant Extracurricular columns
X = df.values.astype(np.float64)
print(X.shape)
(10000, 6)
Note the difference in the number of rows and columns of \(X\). Let’s run through the same steps as above to obtain the solution \(\mathbf{b}\) using \(Q^T\mathbf{y} = R\mathbf{b}\) instead of the normal equation.
Q, R = linalg.qr(X)
Q1 = Q[:10000, :6]
Q2 = Q[:10000, 6:]
R1 = R[:6, :6]
zero_part_of_R = R[6:, :6]
zero_part_of_R
array([[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
...,
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.]])
Note that zero_part_of_R is most of the matrix, but it is indeed just \(0\). All the important information is in the much smaller upper triangular square \(R_1\). Let’s solve.
LHS = Q1.T @ y
b = linalg.solve(R1, LHS)
b
array([ 2.85298205, 1.01843419, 0.48055975, 0.19380214,
0.61289758, -34.07558809])
Finally, let’s verify that these are the same values obtained previously using the normal equations.
np.isclose(b, linalg.inv(X.T @ X) @ X.T @ y)
array([ True, True, True, True, True, True])